license
| license |
|---|
| mit |
GLM-4.1V-9B-Thinking
📖 查看 GLM-4.1V-9B-Thinking 论文 。
💡 立即在线体验 Hugging Face 或 ModelScope 上的 GLM-4.1V-9B-Thinking。
📍 在 智谱大模型开放平台 使用 GLM-4.1V-9B-Thinking 的API服务。
模型介绍
视觉语言大模型(VLM)已经成为智能系统的关键基石。随着真实世界的智能任务越来越复杂,VLM模型也亟需在基本的多模态感知之外, 逐渐增强复杂任务中的推理能力,提升自身的准确性、全面性和智能化程度,使得复杂问题解决、长上下文理解、多模态智能体等智能任务成为可能。
基于 GLM-4-9B-0414 基座模型,我们推出新版VLM开源模型 GLM-4.1V-9B-Thinking ,引入思考范式,通过课程采样强化学习 RLCS(Reinforcement Learning with Curriculum Sampling)全面提升模型能力, 达到 10B 参数级别的视觉语言模型的最强性能,在18个榜单任务中持平甚至超过8倍参数量的 Qwen-2.5-VL-72B。 我们同步开源基座模型 GLM-4.1V-9B-Base,希望能够帮助更多研究者探索视觉语言模型的能力边界。
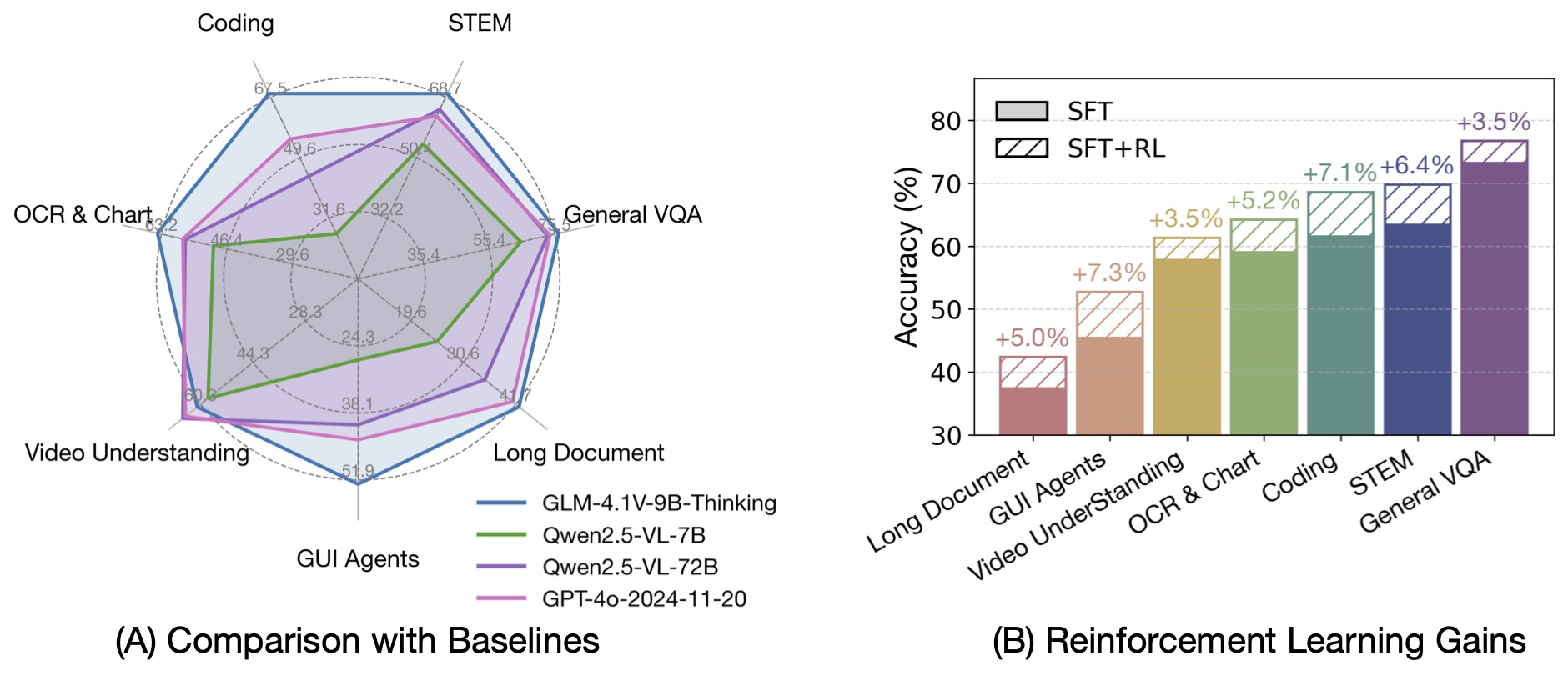
与上一代的 CogVLM2 及 GLM-4V 系列模型相比,GLM-4.1V-Thinking 有如下改进:
- 系列中首个推理模型,不仅仅停留在数学领域,在多个子领域均达到世界前列的水平。
- 支持 64k 上下长度。
- 支持任意长宽比和高达 4k 的图像分辨率。
- 提供支持中英文双语的开源模型版本。
榜单信息
GLM-4.1V-9B-Thinking 通过引入「思维链」(Chain-of-Thought)推理机制,在回答准确性、内容丰富度与可解释性方面, 全面超越传统的非推理式视觉模型。在28项评测任务中有23项达到10B级别模型最佳,甚至有18项任务超过8倍参数量的Qwen-2.5-VL-72B。

快速推理
这里展现了一个使用transformers进行单张图片推理的代码。首先,从源代码安装transformers库。
pip install git+https://github.com/huggingface/transformers.git
接着按照以下代码运行:
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
视频推理,网页端Demo部署等更代码请查看我们的 github。